

I've been actively tinkering around machine learning for past 1 year, yeah it was interesting but still it wasn't giving me enough motivation to learn and explore machine learning more aggressively.
Until I encountered neural networks, working of neural networks is fascinating and how they can be applied on any set of problems whether it is classification, segmentation, Natural language processing and almost every other machine learning domain.
this article is mixture of my learning of neural networks and deep learning throughout the year from various platforms like towardsdatascience, Tensorflow, keras blogs on scale AI, OpenAI and many others and of course some books also.
🤔What is Deep Learning?
To answer that, let's first know a little about neural nets. neural networks are layered structure of neurons kinda like human brain where one side is input and other side is output and some magic in between.
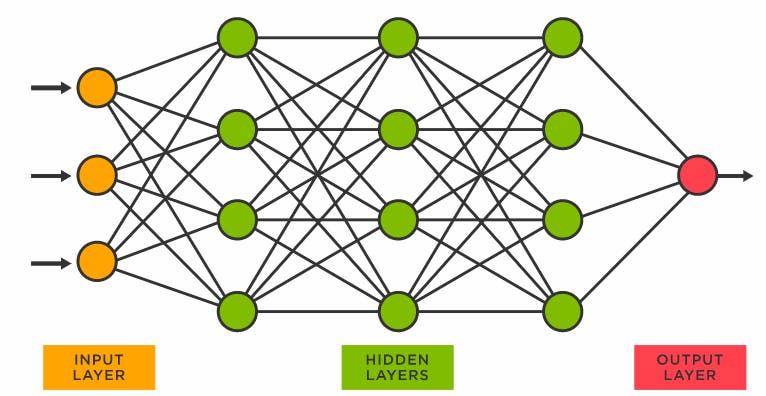
Think of inputs like if you wanted to build a image classifier, input would be every pixel value of greylevel image(intensity values of all the three channel in case of RGB image) and output would be the confidence/probability of model or network about that image predicting what class it would be.
see those circles in hidden layer they are artificial neuron or perceptron which are the basic building blocks of neural networks. all these inputs are interconnect with each neuron of next layer and so on in deep networks.
what make neural networks so special is that these inputs can be anything from value of pixels of an image to words of paragraph, anything that you can represent numerically, regardless of what type input it is. neural networks learns to recognize pattern in the input using hidden layer.
these hidden layers are the magic sauce that decides type of a neural network, whether it is basic neural net, deep neural network, convolutional neural network or some other fancy neural network.
these type of neural network are called feed forward neural network.
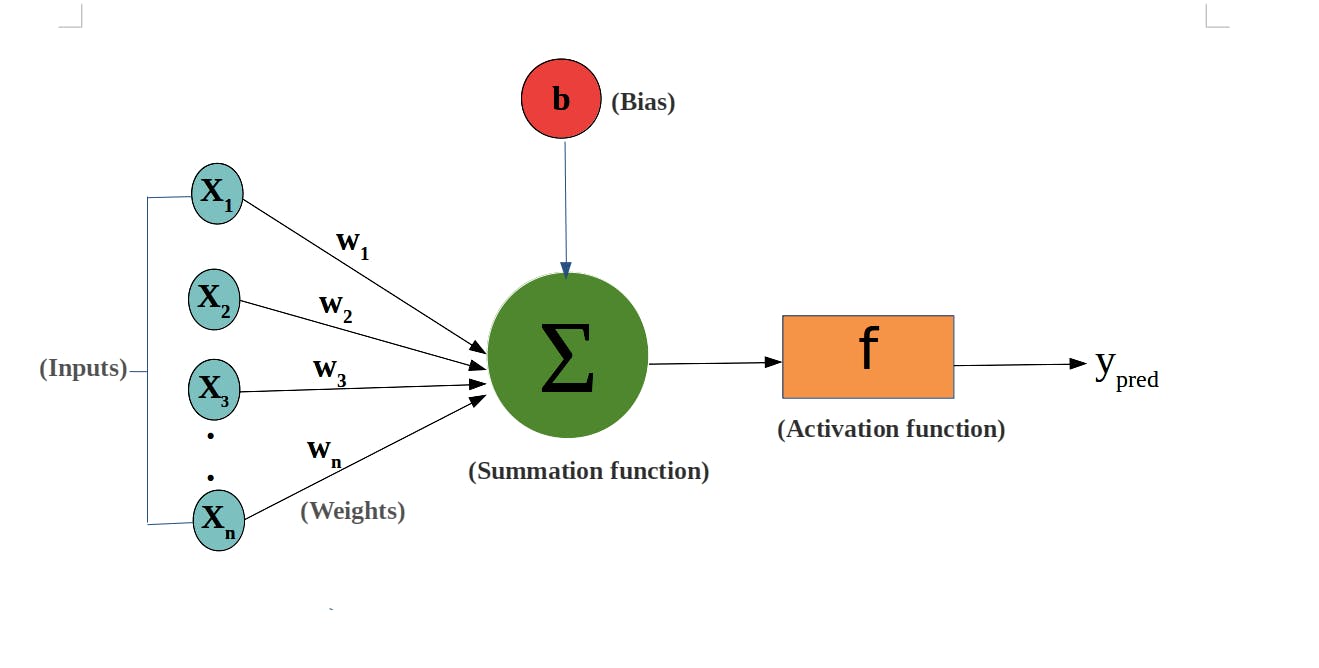
what basically happens in these hidden layers is that each of these artificial neuron(perceptron) have some activation function.
for simplicity think of it as that neuron only output something if input from previous layer neuron to this neuron crosses some threshold.
so, the meaning of threshold of a perceptron is the each neuron have some activation function in which output of last layer is fed and then using this activation function each neuron in that layer generates an output for next, this process is the basis principal of working of neural networks.
with the help activation, weights of connection and bias perceptron's give outputs for next layer are generated
credit:towardsdatascience.com/whats-the-role-of-we..
Weights and Biases
see those paths by which each perceptron is connected with other those are weight which are one of the parameters that we train or changes during training process to increase the accuracy.
each perceptron have some bias factor which is used in calculation of x then fed to activation function of that network to generate output.
Activation function
activation are special function which are used to activate neuron in a layer. we could say activation function are the one which determined the behaviour of out put each neuron.
so, why not use output of previous layer with weight and bias as linear function for input to current layer? Linear function are not well suited to fit the complexity of multidimensional data.
that's specific activation function are used for certain specific task.
Some of the popular activation function use in deep learning:
• Sigmoid
• Relu(rectilinear unit function)
• tanh
we are not going into details here but you can get some idea of these functions by looking at there graph and mathematical equations about how they work.
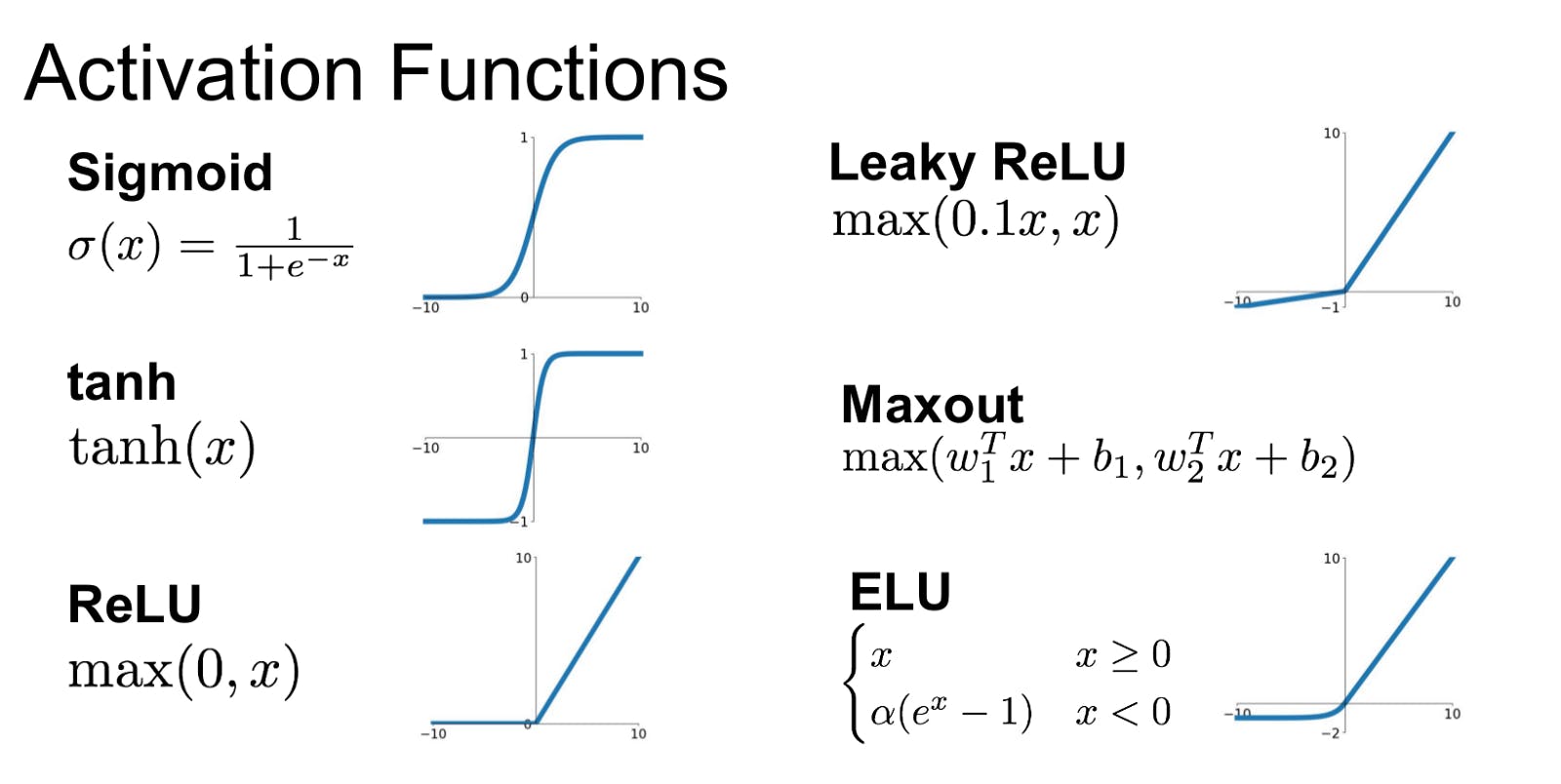 credit:analyticsindiamag.com/what-are-activation-f..
credit:analyticsindiamag.com/what-are-activation-f..
you can learn more activation functions in this article
weights, bias etc are referred as parameters of neural networks and number layers in network, learning rate etc. are referred as hyperparameter.
Using all this stuff
let's take an classical example of image classifier, so we can understand more briefly how this works let's say you want to build an image classifier using this neural network.
step 1:
our training data consist of 10,000 images first we will take our image with grey level from training set in which each image is of dimensions 28*28 which means there are 784 shades of grey in one image and convert it into an array and feed all this into input of our network, therefore we will need 784 input points.
step 2:
our network has 2 hidden layers(neurons in these hidden layers are independent of how many inputs are there).
hidden layers are assigned with random weights and bias initially.
this layers process the data generate output using summation of wx+b and activation function and send them to next layer.
step 3:
Output layer have number of outputs according to number of classes in which we want to classify our data let's say we have only two classes cats and dog. output of last hidden layer is fed to Output layer
step 4:
since our training data is labelled we compare this predicted label output with actual label and calculate error. then with the help of this error weights and biases of hidden layer are adjusted to make predicted label(class) to actual label(class) for example as in our example whether cat or dog.
this is just gist of how neural networks works, there are more complex calculation and transformations involved in making an actual neural networks how errors are calculated and softmax is applied on hidden layers for probability output and how weight and biases are adjusted using back propagation, gradient descents and how second order derivatives are used for optimazation.
there are so many articles and tutorial which explain all this process in easy and comprehensive way referred at the end. you can also refer to standard books for in depth knowledge.
👍so back to our question what is deep learning.
To understand complex pattern or feature extraction in multidimensional data set, very large depth of hidden layers are used with tons of training data to make model useful in practical world applications like apple Voice assistant, open ai's GPT project these kind of machine learning is known as deep learning.
now it's up to you what task you want to perform using these deep networks, each deep learning network is customized for certain specific task and is most suitable for certain category.
👇some of the popular deep learning networks that we will discuss in next article.
• Convolutional Neural Networks(CNN).
• Multilayer Perceptron.
• Recurrent Neural Networks(RNN).
• Generative Adversarial Networks(GAN's).
• Image segmentation(Fast FCN, Mask RCNN, U-net)
But the question is why we need all these other fancy networks when simple neural networks with multiple hidden layer can do the task.
basic neural network works best when our data points are small in size as 2828 dimension but for real practical uses cases input size can be large for example if we use image of dimension 800670 no. of input in our network will 536000 and each of these will be connected to next layer and so on.
In deep networks, backpropagating and adjusting parameters in such networks will be impractical even with today's fast end gpu's and tpu's.
so, to solve this and many other problem different type of deep neural networks are designed to work with particular problem domain.
if you understand basics of how neural networks actually works learning and working with more advanced and practical network is not a hard task, you can work with different type of frameworks and API's like Tensorflow, keras, pytorch, fastai etc. easily.
For more you can refer to: Tensorflow tutorials
Practical Deep learning for coders fast ai
Sentdex Neural network from scratch
Book:
Fundamental of deep learning by Nikhil Buduma(O'Reilly)