



In this article we are going get a broad overview of how convolution neural networks work and their basic architecture. this article is continuation of my previous article on neural networks
🤔Need of CNN's
As I introduced neural networks in previous article, they were working fine. We even classified images using that simple neural network, so what is the need of of these fancy version of neural networks why don't use plain neural networks.
first of all plain neural networks don't scale well, for example in previous article we took images data set with 28*28 dimensionality we had 784 incoming weights for hidden layer as you will see in some standard early stage datasets like MNIST and in this scenario our plain neural network performed fine.
But as soon we increase the size of images and make them more real world like for example a RGB image with (400, 400) dimension, our input weights to hidden layers drastically increases from 784 to 480000(400 400 3) and backpropagating on network with so much parameters and tuning it, will be a tedious task even for today's high performance gpu's and tpu's.
and that's where convolutional neural networks comes in picture, what these plain network were not good in was they were trying to learn everything while what a neural network with convolution kernels does is it tries to extract important feature from dataset and reduces dimension of input dataset, as in case of image important features may be features like edge, shape etc.
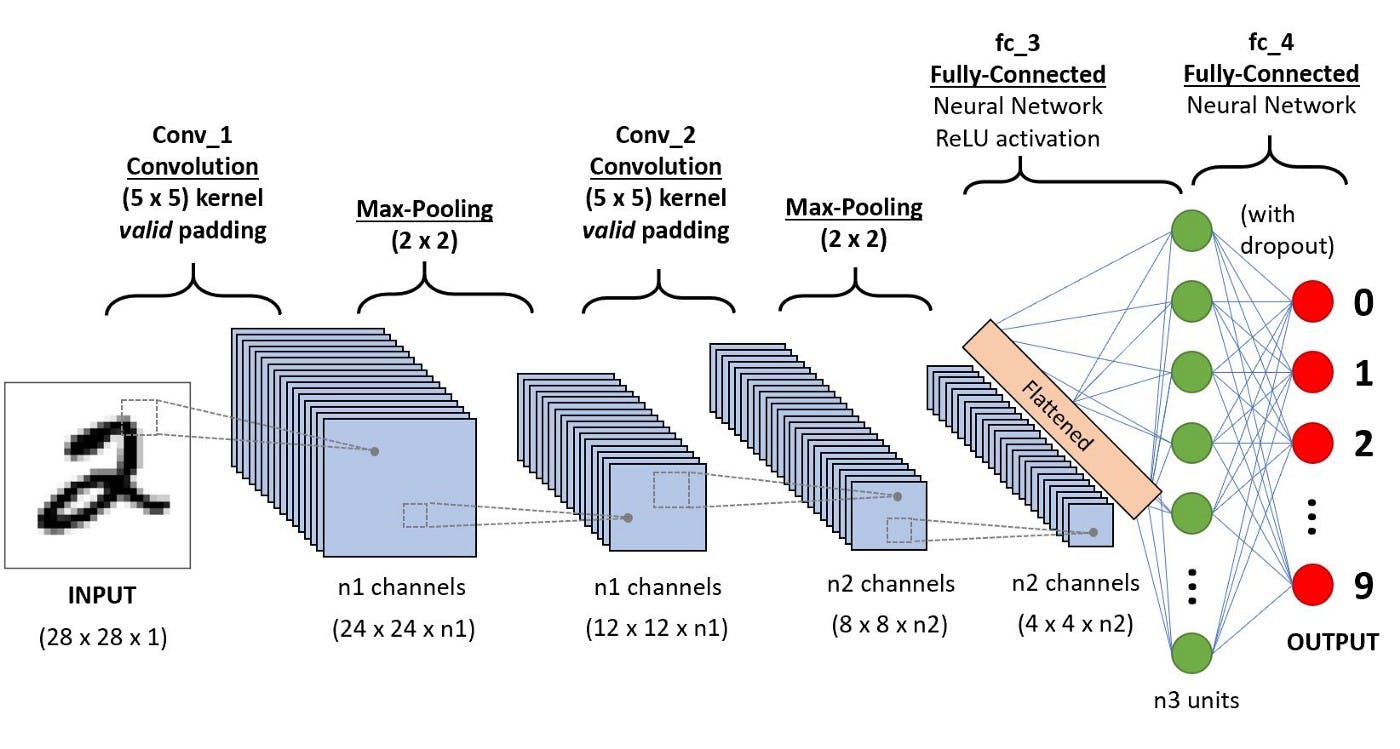 credit:towardsdatascience.com/a-comprehensive-guid..
credit:towardsdatascience.com/a-comprehensive-guid..
secondly CNN's are really good in capturing spatial features like where is some feature in an image space and temporal dependencies.
How CNN extract features?
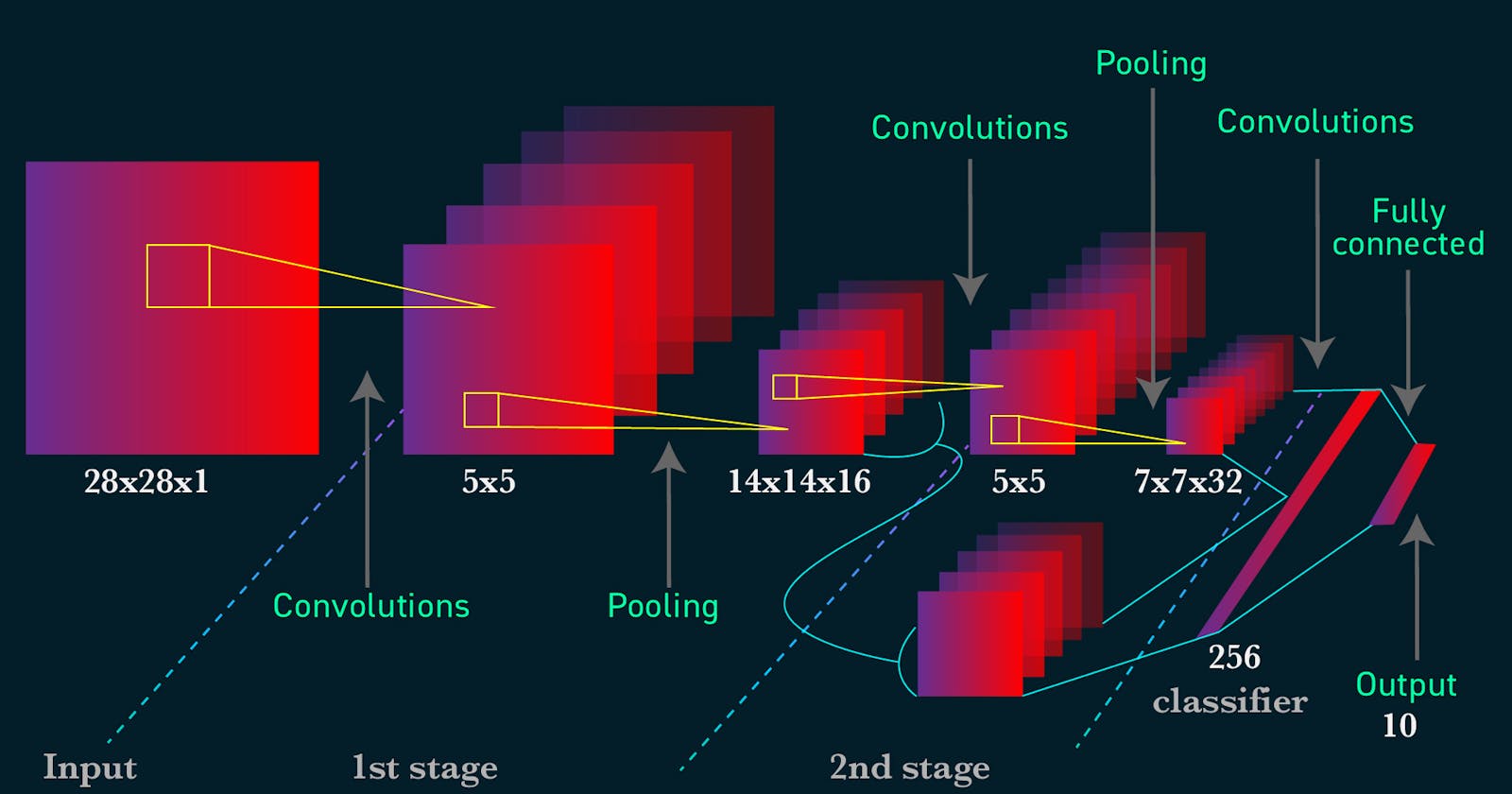
Above is the architecture of Convolutional Neural Network with MNIST dataset, as you can see dimensionality of input image is decreasing gradually but feature maps are increasing gradually.
CNN's extract important features with the help of filter or kernels, these so called called filters are multiplied to the input matrix with gradual sliding to produce some output these outputs are known as features maps.
let's understand feature maps with help of a binary image with more understandable approach.
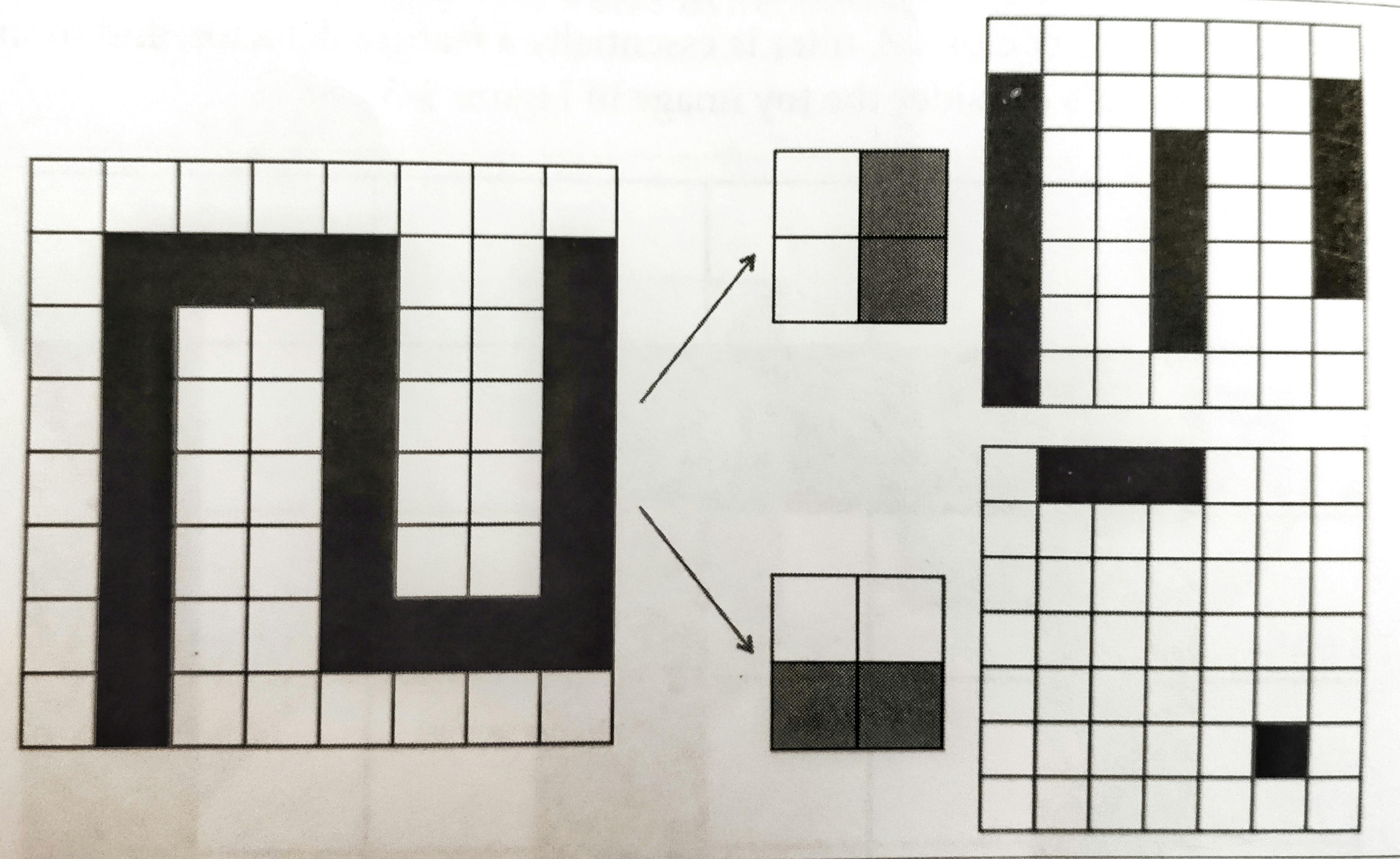 credit:O'reilly
credit:O'reilly
as you can see in above fig. how horizontal and vertical edges in a binary images are detected using 2*2 filters, filter is multiplied with input(just like matrix multiplication) and outputs a feature map with edges highlighted, that's basically what filters and features maps are.
this operation of multiplying filters over input images is known as convolution and result produced by these is known is known as feature map.
In coloured imaged with dimension (w, h, c) where w = width, h = height and c = no. of channels or depth.
In this case dimension of filters is also 3 for eg. (333) filter.
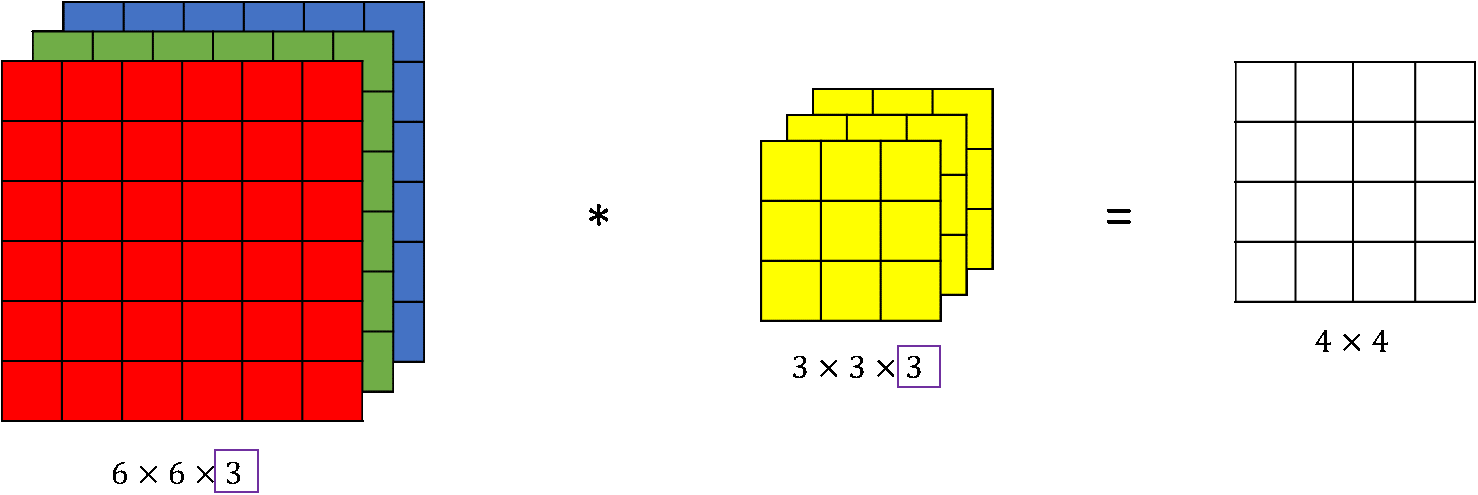
depth of output feature maps is equivalent to the number of filters used in a layer for example if input size is 5 5 with depth(channel) of 3 and 2 filter are used with dimension 3 3 depth of output will be 2.
In Descent Convolutional network there are significant number of these filters.
How CNN's actually work.
Since we have already understood how convolutions are applied on input image, lets try to understand basic functioning of a convolutional neural network.
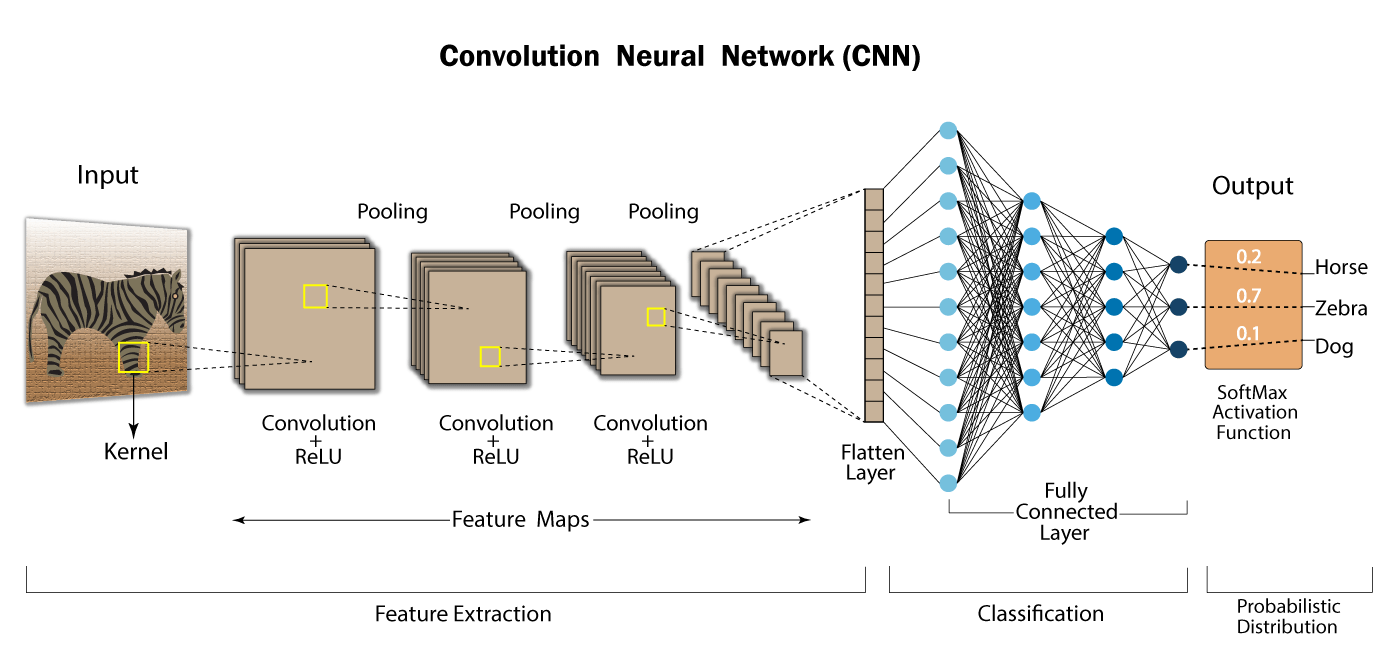
Convolutional layer
as you can see convolutions are applied on our input image of zebra as just like we discussed earlier and some feature maps are generated using this with depth equivalent to number of filters. This layer is known as convolution layer, this is just like other layers as we discussed in plain neural networks but with different type of filters. we also use activation function in convolution layer as we used plain neural network(in this case we are using rectilinear activation function).
Pooling layer
After the convolution operation, pooling operation is applied on the learned feature map to reduce the spatial size of previous layer output(which was convolution layer). Sole purpose of pooling layer is to reduce previous layer size and decrease required computational power.
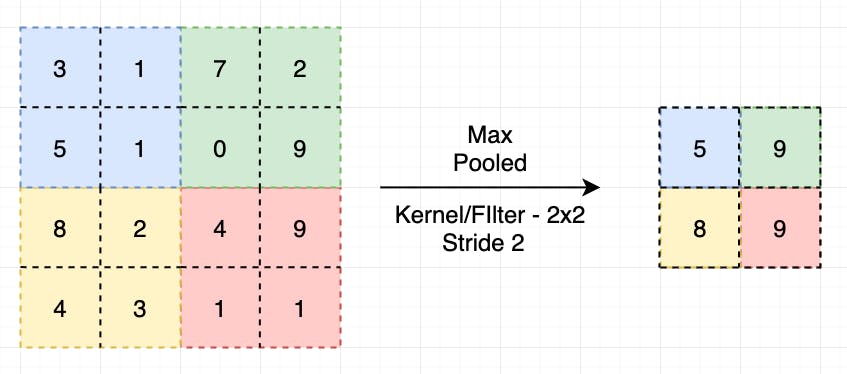
as the size of input is reduced by applying 2 * 2 map pooling in above image.
There are basically two type of pooling Max pooling and Average pooling.
Max pooling
In max pooling max value out of the window size is returned, as in above example window size was 2 * 2 this window is slide over input image and maximum out of the 4 values is returned as output.
Average pooling
In average pooling, average of the element inside the window is returned as output.
then there is multiple repetition of convolution layers with different number of filter and pooling after that.
Very complex and robust features of input images are being learned by the network as we go in more depth of convolution network.

output of last feature map is flattened meaning it is converted into one dimension array and is connected with dense neural network(fully connected neural network) to output the required result, this part is same as plain neural network as we learned in previous article only difference here is that instead of directly feeding input data to this network, output of convolution network is fed to the network which is nothing but some learned features by previous convolution layers.
In this article I only explained the important component of a convolution neural network and how they work, in order to explain the concept easily I have simplified some thing and again there is lot of maths involved which I have avoided to reduce complexity.
goal of this article is to get you started with CNN's in simplified way, you can prefer to books , various article on towardsdatascience and tutorial for in depth knowledge.
Hope, you learnt something from this.